In 15 Minutes, I'll Provide you with The Reality About Deepseek
페이지 정보
작성자 Lon 작성일25-02-08 11:27 조회1회 댓글0건관련링크
본문
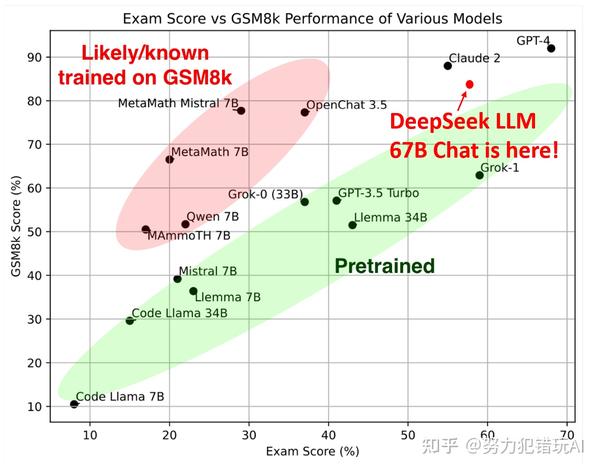 MATH-500: DeepSeek V3 leads with 90.2 (EM), outperforming others. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior efficiency compared to GPT-3.5. One among the principle features that distinguishes the DeepSeek LLM family from other LLMs is the superior efficiency of the 67B Base mannequin, which outperforms the Llama2 70B Base mannequin in several domains, equivalent to reasoning, coding, mathematics, and Chinese comprehension. One of many standout features of DeepSeek’s LLMs is the 67B Base version’s exceptional performance compared to the Llama2 70B Base, showcasing superior capabilities in reasoning, coding, arithmetic, and Chinese comprehension. DeepSeek’s language fashions, designed with architectures akin to LLaMA, underwent rigorous pre-training. Step 2: Further Pre-coaching utilizing an extended 16K window dimension on an extra 200B tokens, resulting in foundational fashions (DeepSeek-Coder-Base). "They’re not using any improvements which might be unknown or secret or something like that," Rasgon mentioned. This feature broadens its functions throughout fields akin to actual-time weather reporting, translation services, and computational duties like writing algorithms or code snippets.
MATH-500: DeepSeek V3 leads with 90.2 (EM), outperforming others. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior efficiency compared to GPT-3.5. One among the principle features that distinguishes the DeepSeek LLM family from other LLMs is the superior efficiency of the 67B Base mannequin, which outperforms the Llama2 70B Base mannequin in several domains, equivalent to reasoning, coding, mathematics, and Chinese comprehension. One of many standout features of DeepSeek’s LLMs is the 67B Base version’s exceptional performance compared to the Llama2 70B Base, showcasing superior capabilities in reasoning, coding, arithmetic, and Chinese comprehension. DeepSeek’s language fashions, designed with architectures akin to LLaMA, underwent rigorous pre-training. Step 2: Further Pre-coaching utilizing an extended 16K window dimension on an extra 200B tokens, resulting in foundational fashions (DeepSeek-Coder-Base). "They’re not using any improvements which might be unknown or secret or something like that," Rasgon mentioned. This feature broadens its functions throughout fields akin to actual-time weather reporting, translation services, and computational duties like writing algorithms or code snippets.
 These pressures come on high of army aggression from Russia in Ukraine and elsewhere, austerity in public services, elevated vitality costs, stagnant residing standards, a difficult green transition, demographic decline, and anxiety about immigration and cultural diversity. DeepSeek LLM 7B/67B models, including base and chat variations, are launched to the public on GitHub, Hugging Face and in addition AWS S3. Open-sourcing the brand new LLM for public analysis, DeepSeek AI proved that their DeepSeek Chat is much better than Meta’s Llama 2-70B in numerous fields. By open-sourcing its models, code, and knowledge, DeepSeek LLM hopes to advertise widespread AI research and industrial purposes. The prices to practice models will continue to fall with open weight models, especially when accompanied by detailed technical reports, however the pace of diffusion is bottlenecked by the necessity for challenging reverse engineering / reproduction efforts. While a lot of the progress has occurred behind closed doors in frontier labs, we've seen loads of effort in the open to replicate these results. However, I did realise that multiple makes an attempt on the same take a look at case didn't always lead to promising outcomes.
These pressures come on high of army aggression from Russia in Ukraine and elsewhere, austerity in public services, elevated vitality costs, stagnant residing standards, a difficult green transition, demographic decline, and anxiety about immigration and cultural diversity. DeepSeek LLM 7B/67B models, including base and chat variations, are launched to the public on GitHub, Hugging Face and in addition AWS S3. Open-sourcing the brand new LLM for public analysis, DeepSeek AI proved that their DeepSeek Chat is much better than Meta’s Llama 2-70B in numerous fields. By open-sourcing its models, code, and knowledge, DeepSeek LLM hopes to advertise widespread AI research and industrial purposes. The prices to practice models will continue to fall with open weight models, especially when accompanied by detailed technical reports, however the pace of diffusion is bottlenecked by the necessity for challenging reverse engineering / reproduction efforts. While a lot of the progress has occurred behind closed doors in frontier labs, we've seen loads of effort in the open to replicate these results. However, I did realise that multiple makes an attempt on the same take a look at case didn't always lead to promising outcomes.
We further evaluated a number of varieties of every model. CompChomper gives the infrastructure for preprocessing, operating a number of LLMs (domestically or in the cloud via Modal Labs), and scoring. It exhibited remarkable prowess by scoring 84.1% on the GSM8K arithmetic dataset without high quality-tuning. The LLM was trained on a big dataset of two trillion tokens in both English and Chinese, employing architectures resembling LLaMA and Grouped-Query Attention. The 7B model utilized Multi-Head consideration, while the 67B model leveraged Grouped-Query Attention. DeepSeek Chat has two variants of 7B and 67B parameters, which are educated on a dataset of 2 trillion tokens, says the maker.
댓글목록
등록된 댓글이 없습니다.